All things should be made as simple as possible, but no simpler. -Albert Einstein
4.1 Quajects
Quajects are the building blocks out of which all Synthesis kernel services are composed. The name is derived from the term "object" of Object-Oriented (O-O) systems, which they strongly resemble [32]. The similarity is strong, but the difference is significant. Like objects, quajects encapsulate data and provide a well-defined interface to access it. Unlike objects, quajects use a code-synthesis implementation to achieve high performance, but lack high-level language support and inheritance.
Kernel quajects can be broadly classified into four kinds: thread, memory, I/O, and
device. Thread quajects encapsulate the unit of execution, memory quajects the unit of
data storage, I/O quajects the unit of data movement, and device quajects the machine's
interfaces to the outside world. Each kind of quaject is defined and implemented independently.
That might not work. Integer division by zero is defined to raise #DE, incidentally the very first in the interrupt vector. Floating point division by zero silently produces infinity or NaN without informing the supervisor.
> Modulate the CPU temperature by running code. The OS decodes the signal. Use message passing that involves OFDM, LDPC, ASN.1, and digital signatures.
I like how you mixed this in with real suggestions.
It's an excellent suggestion if the code you're trying to communicate with is not actually the kernel, but rather other code on the machine that the kernel is attempting to prevent you from communicating with. Except for the ASN.1 part. That's never a good idea.
Is PC-AT style "get the keyboard controller to reset the CPU, then have special BIOS code detect situation and jump to your code?" still available in modern systems? Real mode is sortof a supervisor mode.
Of course you would have to make the KBC low level accessible to user mode which may cause issue processing legacy input devices. Plus having to reinitialise protected mode every system call might cause some efficiency issues.
IIRC enough of the KBC is still present that this might actually work, another question is whether modern UEFI firmware actually handles the SW-induced reboot.
As for entering and exiting protected mode: that is in fact surprisingly fast operation assuming that all the relevant data structures are still in place. In fact DOS XMS managers (and VxD-based Windows) switch between PM with vm86, true real mode and various unreal-ish (ie. real mode with weird values in descriptor shadow registers) modes quite regularly.
for security reasons (ASLR), the vsyscall page is implemented on modern kernels by unmapping the page, trapping the page fault, and emulating the system call.
the recently introduced io_uring interface provides an interface to set up a buffer ring which is asynchronously polled by the kernel for system calls to execute.
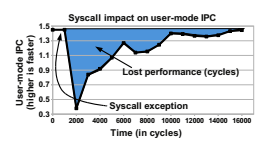
Before you look at these benchmarks and concluded system calls are cheap, please be aware the real cost is not 100 cycles, it's 100 cycles plus the cost of clobbering your L1 and often L2 cache, instruction cache, TLB, etc. This is made worse on many current systems due to mitigations for Intel's buggy processors. The real cost is often more than 10,000-30,000 cycles. Which is why for anything very syscall heavy, like a network server handling millions of very small packets per second you get more than an order of magnitude better performance by bypassing the kernel and avoiding syscalls altogether. It's also why threads are "faster" than processes even although they're implemented the same way, no need to flush the TLB on context switch.
The current trend seems to be to use ring buffers between the kernel and userspace (see: perf, io_uring, this proposal https://lwn.net/Articles/789603/), which reduce this overhead.
At the lowest level this is how it works, so using ring buffers as the abstraction makes tremendous sense. Plus it can be done safely without requiring a context switch on the fast path, with a little care.
Its also easy to naturally batch things. When the load is low the batch size is 1, and then it naturally grows as more work gets queued during processing of the prior work.
BPF is more like moving your compute into the kernel, but it achieves the same effect - you avoid context switch overhead associated with syscalls. Kernel bypass is typically using ring buffers and a poll-mode network driver (e.g. DPDK, snabbswitch) and skipping the whole kernel network stack.
Although you are technically correct in that the cost of system calls on most systems is high, your post also implies to a casual reader that the cost is fundamental. This is not true. As demonstrated in the benchmark, the hardware cost of systems calls/trapping is quite low. Even accounting for hardware workarounds (which were not even known about when the common consensus decided system calls were slow), excepting the case of hardware virtualization which has much more expensive mitigations, the fundamental cost is a fraction of the actual cost.
The majority of the cost (~90+%) is actually due to software. In the system call case this is the implementation of the system call. In the context switch case this is usually the cost of the scheduling decision. These operations take material amounts of time and access memory which evicts user caches. It is in speeding up the software component that real gains can be made. This is not to say that system calls could ever be made "free" since function calls/loads/stores will still be ~100x faster, but the cost would probably be ~10% of the current cost if they software component could magically be made instant.
As an example of what I am talking about, there is this talk by Google from 2013 [1] which describes a "fast context switch" system call (benchmark at 18:40). This "context switch" knows what it is switching to which lets it bypass the scheduling decision in normal context switches. As a result it takes ~170 ns (which is pretty close to the hardware cost mentioned in the OP) vs 2000 ns of a normal context switch.
I could go into more detail as to some of the causes of the underlying software costs, but that is a discussion for another time, so I will just leave this off with summarizing my point.
tl;dr: System calls are slow. It is due to the software implementing them, not the hardware.
Fun fact, not only can you use iret to return to user-mode from kernel-mode and kernel-mode from kernel-mode (as footnote 5 mentions), you can also use iret to return from user-mode to user-mode. It is a handy way to restore RIP, RSP, and RFLAGS at the same time. .NET CoreCLR uses it during exception handling on Unix:
The problem is that on i386 the TLB entries are keyed only by linear address and not by page table that the entry came from and writing into the page table register (even rewriting the same value) is documented as triggering TLB flush.
On typical RISC platforms that directly expose TLB to supervisor TLB entries usually have few bits that can be used to record for which process is the entry valid and thus there is no need to flush whole TLB on each task switch.
(Modern i386 CPUs actually have somewhat similar mechanism, but it is only usable by hypervisors, not by normal operating systems)
What do you mean? If you can record the data in the first place you can probably save it. If you mean making some kind of workload or benchmark, couldn't you write some code to do it? It's probably somewhat inefficient because you can't write to it directly but you can get pretty close.
One of the ways that many operating systems (I'm fairly certain that Windows did this at one point) implemented syscalls long ago was to execute an illegal instruction, because this was the fastest way at the time to transition to kernel mode. x86 even has a specific opcode that is guaranteed to never be used aka always be an illegal instruction
OK, I really don't know anything about assembly/OSes, but if the price of going to kernel mode with sysenter/syscall is smaller than a not that pricey(the article says it's less than a single 64-bit integer division), does that mean microkernels can utilize that to improve performance?
What are the shortcomings of the method compared to interrupts?
On microkernels the issue is usually not with syscall performance but with essentially every operation causing a task switch which on i386 causes TLB flush (which in post-Spectre days seems somewhat moot) and in many cases involves interacting with task scheduler.
(QNX uses interesting hack to sidestep this: the message passing interface does not really pass messages, but is simply cross-addressspace call/return that in essence temporarily moves a thread to different process without rescheduling anything)
>Synthesis: An Efficient Implementation of Fundamental Operating System Services
>This dissertation shows that operating systems can provide fundamental services
an order of magnitude more efficiently than traditional implementations. It describes the
implementation of a new operating system kernel, Synthesis, that achieves this level of
performance.
>The Synthesis kernel combines several new techniques to provide high performance
without sacrificing the expressive power or security of the system. The new ideas include:
>- Run-time code synthesis -- a systematic way of creating executable machine code
at runtime to optimize frequently-used kernel routines | queues, buffers, context
switchers, interrupt handlers, and system call dispatchers | for specific situations,
greatly reducing their execution time.
>- Fine-grain scheduling -- a new process-scheduling technique based on the idea of
feedback that performs frequent scheduling actions and policy adjustments (at submillisecond intervals) resulting in an adaptive, self-tuning system that can support
real-time data streams.
>- Lock-free optimistic synchronization is shown to be a practical, efficient alternative to
lock-based synchronization methods for the implementation of multiprocessor operating system kernels.
>- An extensible kernel design that provides for simple expansion to support new kernel
services and hardware devices while allowing a tight coupling between the kernel and
the applications, blurring the distinction between user and kernel services.
>The result is a significant performance improvement over traditional operating system implementations in addition to providing new services.
>Alexia Massalin’s 1992 PhD thesis has long been one of my favorites. It promotes the view that operating systems can be much more efficient than then-current operating systems via runtime code generation, lock-free synchronization, and fine-grained scheduling. In this piece we’ll only look at runtime code generation, which can be cleanly separated from the other aspects of this work.
Valerie Henson's commentary on the Synthesis kernel (2008) (lwn.net)
KHB: Synthesis: An Efficient Implementation of Fundamental Operating Systems Services
>When I was but a wee computer science student at New Mexico Tech, a graduate student in OS handed me an inch-thick print-out and told me that if I was really interested in operating systems, I had to read this. It was something about a completely lock-free operating system optimized using run-time code generation, written from scratch in assembly running on a homemade two-CPU SMP with a two-word compare-and-swap instruction - you know, nothing fancy. The print-out I was holding was Alexia (formerly Henry) Massalin's PhD thesis, Synthesis: An Efficient Implementation of Fundamental Operating Systems Services (html version here). Dutifully, I read the entire 158 pages. At the end, I realized that I understood not a word of it, right up to and including the cartoon of a koala saying "QUA!" at the end. Okay, I exaggerate - lock-free algorithms had been a hobby of mine for the previous few months - but the main point I came away with was that there was a lot of cool stuff in operating systems that I had yet to learn.
>Every year or two after that, I'd pick up my now bedraggled copy of "Synthesis" and reread it, and every time I would understand a little bit more. First came the lock-free algorithms, then the run-time code generation, then quajects. The individual techniques were not always new in and of themselves, but in Synthesis they were developed, elaborated, and implemented throughout a fully functioning UNIX-style operating system. I still don't understand all of Synthesis, but I understand enough now to realize that my grad student friend was right: anyone really interested in operating systems should read this thesis.
>Massalin's Synthesis kernel [10] stands out to me as another example that for me crosses the boundaries and is both outstanding engineering and art in challenging the ideas of how systems could be built in ways that make me look at it just as much because of the beauty of it as because of the practical ideas. (The main thing it brought was the idea of making the kernel adapt to its clients by generating custom code for system calls; to me it is art because it turned the idea of a kernel as something static on its head; and conceptually we're still just scraping the very surface of dynamic code generation in kernels that Massalin's thesis started playing with). There are many works like that, where the specific implementations are irrelevant - nobody uses the Synthesis kernel - but where the ideas are as important as any expressed in more overt or "intentional" art.
>ggm: It feels to me like if you can do runtime code call checks, and confirm which actual calls you make, then stripping the bits of libc and associated libraries out, being left with only the strictly required calls, and then by extension the syscalls, and then by extension the kernel elements, is actually possible a lot of the time. So, library -> reduced library -> reduced calls -> reduced syscalls -> reduced kernel state is a sequence or set or something, of applied minimisations which can be done, if you can predict all the call paths in your code and their dependencies.
>NelsonMinar: That sounds a little like the ideas in the Synthesis kernel, the idea of the kernel JIT-compiling itself to optimize your code path.
> Although Call Gates are the somewhat official way of implementing system calls in the absence of the more modern alternatives discussed below, I’m aware of no use except by malware.
I think 386BSD and early FreeBSD used call gates for syscalls.
I wonder if mainstream CPUs will ever get back to being truly programmable with software instructions, instead of running off and speculating on what you might do next.
{kind=link}
The 0xf1 byte, an "icebp" or "int1" instruction
In 32-bit code, use an FPU stack underflow
In 64-bit mode, access a non-canonical address
In 32-bit code, use the "into" instruction
Write data using a segment selector that goes beyond the LDT limit
With the alignment checking enabled, do a misaligned memory operation
Of course, we can also do system calls without causing exceptions. Examples:
Write the system call number to a well-known memory location that the OS will poll
Modulate the CPU temperature by running code. The OS decodes the signal. Use message passing that involves OFDM, LDPC, ASN.1, and digital signatures.