And of course drawline(Point, Point) isn't clearer at all imo. What's the coordinate system? What are the units? Any performance notes on this function? Etc. I'll be checking the documentation the first time anyway.
void do_something(vector<string>& v)
{
string val;
cin>>val;
// ...
int index = 0; // bad
for(int i=0; i<v.size(); ++i)
if (v[i]==val) {
index = i;
break;
}
// ...
}
this is shown to be inferior to the find() version. Again, it's only inferior until the very common case where you're doing something else with the index, which is pretty common during debugging. Then you'll be rewriting the above "bad" version anyway.
Similar problems other higher order functions like for_each().
> What's the coordinate system? What are the units?
Good question. Where are you going to look that up? In the documentation of drawline?
Should drawrect, drawcircle, etc..., also include documentation about the coordinate system/units?
Of course not, that information should be centralized. That's where Point come in.
And that's just a detail, the main advantage of using a class is that is abstract details.
In the Point class, you may want to switch from int to int64_t without having to revisit all the methods.
That's the textbook explanation for this stuff, and matches what we see in the document. But I'm with the grandparent: this sort of pedantry fails badly in real-world code. What happens when you want to combine that rectangle implementation with someone else's geometry library which has its own notion of Point?
This kind of nonsense is just a recipe for everyone spending lines of code and neural cycles on a bunch of junk that will just be unpacked back into the underlying representation anyway in order to be used in the real world.
Don't do it. Simplicity trumps almost everything in real engineering. Abstract where abstractions add real value (which usually means "hide non-trivial amounts of code) and not where they do nothing but "document" stuff.
In this case the usage is clear (and IIRC I think most IDE's will avoid omitting lib1:: and lib2:: in compiled code even if you do). The whole point of namespacing is to avoid the name collision issues that are (were?) inherent to C.
I think the point may have been to call a function in one library with the arguments of types from the other library, so that you need to write less glueing code. But in that case, you don't actually know that the point types are compatible (they might be), especially since their internal details can change. I don't think this is about name collision.
Exactly. The point is that the abstracted Point hides implementation details like the underlying representation, which is good as far as it goes because it prevents goofs like overflow and trucation due to incorrect type conversions, etc...
But the second you need to match that abstraction to the code from some other developer which doesn't use it, you need that underlying representation back again. And this kind of mismatch isn't an uncommon edge case, it's the pervasive truth of modern development.
Basically: C++ can't win here, and it would be better not to try IMHO.
> you need that underlying representation back again.
But that's kind of a problem: while the underlying representations might be perfectly compatible, and you might know that for sure, that is not at all guaranteed. If you have a function that takes (int, int, int, int) instead of (Point1, Point1), Point1 = (int, int), that would not help you very much when Point2 = (int32, int32) (e.g., sometimes libraries make assumptions about internal representations, sometimes they don't).
Using low-level primitives everywhere like that can be a very misleading kind of simplicity - it might disappear. That C++ makes you reckon with the possibility that Point1 /= Point2 is supposed to tell you something about what you can know for sure about those types.
I have this issue occasionally, switching between sf::Vector2, b2Vec2, gVec2, etc. Something like drawLine({v.x,v.y},{w.x,w.y}) usually works in a lot of these cases, but I don't mind explicitly converting between representations in order to fulfil an interface.
The `(int, int, int, int)` version doesn't really help here though, because just because both libraries have int parameters doesn't mean they're compatible (eg as said above, could be different coordinate systems - but they look compatible!). At least with two point types its obvious that you need to convert between them.
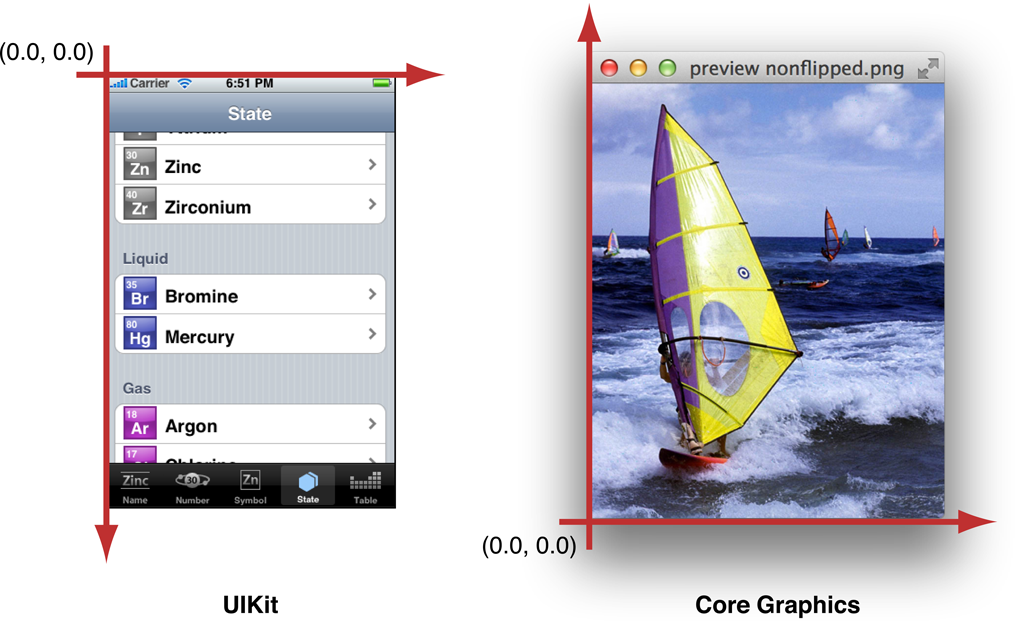
What about the case when one library calls the origin the top left of the screen and the other library considers the origin the bottom left of the screen?
But... the compiler can't catch that incorrect translation code. The developer takes MyPoint and unpacks it into two doubles, then hands it to the YourPoint constructor and forgets to invert Y.
That's the point. The compiler is useless here, and this kind of glue code is probably 60+% of what developers are actually writing in practice.
But this site wants us to sit down and write a ton of boilerplate to handle a "Point" abstraction (complete with a full operator suite I'm sure, yada yada) just to solve a problem that can't be solved in the first place.
Well, you probably wouldn't be able to construct a UIKit::Point from a CoreGraphics::Point in the first place (these aren't C++ libraries but let's just go along for the analogy) if they didn't know about each other. You'd have to strip out the X and Y yourself, and this is the moment where you should be wondering if that's legal to do.
And if the libraries do know about each other then it's even better, because you can just say
CoreGraphics::Point cgp = CoreGraphics::Point(0, 0);
UIKit::Point p = UIKit::Point(cgp);
and p could already be in the right coordinate frame.
Anyways, this isn't some constant thing. Java developers typically like abstraction, ruby guys like passing raw hashes and strings/symbols everywhere. My preferences change based on language, codebase size, and how many people I'm going to be working with.
The summary is that we had two different coordinate systems in play and had many bugs caused by passing values in the wrong coordinate system around. By making the different coordinate systems different classes everything became explicit and checked by the compiler. We completely eliminated a whole class of bugs from our program.
The great thing about using an int is that it can be anything (integer). It can be an x coordinate, or the number of eggs or a selection between multiple options.
The bad thing about using an int is that it can be anything, and sooner or later you will pass the number of eggs into a function that really wants an x coordinate.
I prefer having member functions that convert to a different value, and friend functions that create instances from another type:
Distance d = feet(7);
d += meters(3);
std::cout << d.yards();
Distance d2 = 3; // I won't compile
This assumes that you want to mix units, not defeat it. It all ends up being very efficient; use MKS for the underlying representation. You can multiply, add, and so on, quite efficiently; the only conversions happen on input and output.
> That information can be encoded into the class type
This. I did the very same thing when dealing with some code that was frequently converting between three coordinate systems. Using Haskell code duplication was close to non existent and still type-safe. Not wanting to sound too fan-boyish ... but that was one of the first times that I realized that a good type-system can help you prevent whole classes of bugs.
I don't enjoy converting stuff between different formats for different libraries either, but sticking associated bits of data together really does make sense. With a function that just takes four integers, you can't easily distinguish between two Points or a Rect, for example.
Plus, a lot of problems are solved by namespacing and something like this:
At my job, we have namespace::MathConvert() which takes instances of one type, and returns const refs to other types (assuming they are binary compatible), for the case of one Point type to another.
If you're working with a lot of different point types then it probably makes sense to define your own point type that provides type conversion to all the other point types used in your codebase. That way you're not coupled to one library's point type in your own code and can add extra functions, etc. to the point class that you might need. You can also explicitly control stuff like what frame of reference your coordinate system is in and your type conversion functions handle converting to different frames of reference for other point types.
> several libraries where each defines its own "Point".
Same problem where each library defines its own "String".
Would be nice if the standard libraries would define such basic types and everyone would just use the same ones.
This might work better without OO kitchen sink approach to types. Just standardize a simple data layout or interface and leave the possibility for libraries to define their own functionality in extension methods.
Still, as Herb Sutter asked at CppCon 2015: "How many of you have your own homegrown string types at your companies? ... Don't lie. ... Right. And those of you who didn't put up your hand and are just bashful, ... we know we have them." [1]
The problem with std::string is, it was useless in the real world because its interface is basically unsuitable for handling Unicode. That's why every project that cares about i18n had to define its own string class to get anything done.
Only with C++11 did they add std::u16string, which is at least suitable for the (horrible) UTF16 encoding. Maybe we'll get an UTF8 capable std::string class in another 20 years.
You've always had the ability to put utf-8 data in std::strings, but you have to keep track of which strings are encoded. C++11 adds functions to convert to utf-8 (and utf-16 and utf-32), http://en.cppreference.com/w/cpp/locale/codecvt .
Note that with a long list of int values, it's also fairly easy to get the order wrong. Having a proper point type makes this less likely, as well as making the intent explicit.
Someone mentioned using an initializer list, which is a pretty good option if you don't want to be explicit. However, writing a small helper function or class to automatically (and using constexpr, at compile time) convert between different kinds of points can achieve the same thing without losing the contextual benefits.
For me, I don't care that
drawline(Point(vec.x1, vec.y1), Point(vec.x2, vec.y2))
is more or less clear. I mainly care about the fact that you can't easily tell which of these is correct:
drawline(Point(vec.x1, vec.y1), Point(vec.x2, vec.y2))
drawline(Point(vec.x1, vec.x2), Point(vec.y2, vec.y2))
{kind=link}
for example
this is only "clearer" until you find yourself at the very common case where you use several libraries where each defines its own "Point".Now you're writing something like
Pretty ugly!And of course drawline(Point, Point) isn't clearer at all imo. What's the coordinate system? What are the units? Any performance notes on this function? Etc. I'll be checking the documentation the first time anyway.
this is shown to be inferior to the find() version. Again, it's only inferior until the very common case where you're doing something else with the index, which is pretty common during debugging. Then you'll be rewriting the above "bad" version anyway.Similar problems other higher order functions like for_each().